Coordinator
All MetaData modification are mainly executed by three different roles in LinDB.
- Master: Execute all Metadata modification and delivery them to other components in the cluster through ETCD, and the Master is elected in Broker;
- Broker: Listens all states in the cluster;
- Storage: Listens status of the storage cluster where its located;
Why is Master in charge of all Coordination of the entire cluster?
- Broker actually acts as compute node with read/write operations. Coordination task of the state information is placed in the broker layer so that it is able to access the state information of all the storage nodes in the lower layer.
- Metadata changes are frequent and are all lightweight;
- Requires the computing ability to reduce query of a same database from multiple IDCs;
What information needs to be processed?
- Database DDL operations;
- Storage Node Management;
- Runtime Parameter Adjustment;
- Storage/Broker State Management;
Overview
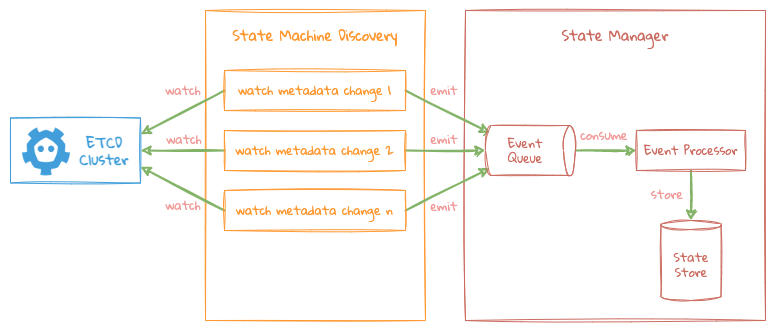
All scheduling operations are processed based on the basic framework logic of the figure above, each role listens for its own interested data change operations in ETCD.
- Each character spawns an asynchronous goroutine for the Metadata they care about to listen for changes via different keys in ETCD, each key is listened by separated goroutine;
- When the listening key is changed, the corresponding goroutine submits the event to the event-queue in State Manager. Then the State Manager will start a global thread to process the change work of all events uniformly, and store the processed result in the State Manager's State Store;
- All external status information is obtained directly from the State Manager's State Store without ETCD, so LinDB will still work when ETCD is down;
Master
The Master is responsible for most Metadata changes, it is elected from currently surviving Broker nodes by preemptively election. In brief, each Broker node registers the Master KEY concurrently, the first node will become Master;
At the same time, each Broker will also watch Master Key, If the information on Master Key is lost, the election will be re-initialized, so that each Broker will know who is the Master and able to forward requests to Master node;
Master KEY: /{broker namespace}/master/node
Successfully Election KEY: /{broker namespace}/master/node/{broker node}
Post-Election Key: /{broker namespace}/master/elected/{broker node}
Master is responsible for the following state machines:
- Storage Config State Machine;
- Database Config State Machine;
- Shard Assignment State Machine;
Storage config
Watch KEY: /{broker namespace}/storage/config
- The user can submit storage cluster configuration information to any broker node, then the Broker node just simply writes the configuration information to
/storage/config/{cluster name} - Master establishes a Storage-Live-Node State-Machine Watching mechanism for each Storage cluster based on the configuration information to trace the survival of each Storage cluster node;
- Each Storage Cluster Watches the survival situation of Storage nodes, and write the overall storage status information to
/state/storage/cluster/{cluster name}for usage by [Storage Cluster Status State Machine] (#storage-status);
The Watch mechanism for each Storage Cluster is as follows:
- Establish connection with ETCD of the Storage cluster based on the configuration information of the Storage cluster;
- Watch Storage cluster node survival KEY:
/active/nodes(note that unlike brokers/active/nodes, it corresponds to the storage registration information); - When each Storage node starts, registers the node information below the corresponding KEY:
/live/nodes/{storage node id};
Database config
Watch KEY: /{broker namespace}/database/config
- The user can submit the database DDL to any broker node, which broker will just write the configuration to ETCD;
- Through the change of Watch KEY, the Master knows that it needs to assign the corresponding database, then generates a Shard Assignment according to the node status information of the current Storage cluster, and sends the Shard Assignment task to the corresponding nodes;
TIP
Shard Assignment : Describe the detail of each DataBase Shard;
Name: Database Name;
Option: Configuration information for the storage engine;
Shards: Assignment information for each Shard;
Each Shard assignment includes the following information:
ShardID: Shard's ID;
Replicas: The information of all Replicas under the Shard corresponds to the information in the Node ID above;
Shard assignment
Watch KEY: /{broker namespace}/database/assign
- Through watching this key, the Broker elects the leader of the corresponding data partition according to the current online node status of the target Storage cluster when the number of data shards changes, then sends the election result to the corresponding node;
Storage Live Node
Watch KEY: /{storage namespace}/live/nodes
By watching survival status of each node of the corresponding Storage cluster, broker controls whether the shard needs to re-elect a new Leader node, and traces the survival status of the current replica.
- When a shard leader was down, a new leader will be elected from currently surviving replica nodes. If no more replica node, the data shard will be marked as offline;
- When a replica shard was down, then it will be removed from the list of surviving replicas;
- When a new node was up, then it will be added to the list of surviving replicas, while the shard was already offline, this node will be elected as the new leader of this shard, then the shard will be marked as on-line again.
Broker
Broker is responsible for the following state machines:
- Live Node State Machine;
- Database Config State Machine;
- Storage Status State Machine;
Live node
Watch KEY: /{broker namespace}/live/nodes
- When the Broker starts, it will register its own information under the Watch KEY:
/live/nodes/{broker node}; - Through the Watch KEY, each broker knows which nodes are alive in the current broker cluster;
Database config
Watch KEY: /{broker namespace}/database/config
- Through this watch key,Broker knows every database configuration.
Storage state
Watch KEY: /{broker namespace}/storage/state"
- Value of Watch KEY is written uniformly by the Master. The Master will watch the survival of each node in each Storage cluster, and write the final cluster information under the Watch KEY. For details, please refer to [Storage Live Node State Machine](# storage-live-node);
- Through watching of this Watch KEY, overall status information of each Storage cluster will be known;
- When processing a query request, this key will be used to obtain status information of the corresponding Storage node;
- When processing a write request, this key will be used to obtain leader node of the target shard, then a corresponding data write channel will be established;
Storage
Storage is responsible for the following state machines:
- Live Node State Machine;
- Shard Assignment State Machine;
Live node
Watch KEY: /{storage namespace}/live/nodes
- When Storage starts, it will register its own information under the Watch KEY, namely
/live/nodes/{storage node}; - By watching of this KEY, each Storage knows which nodes are surviving in the current Storage cluster;
Shard assignment
Watch KEY: /{storage namespace}/database/assign
- By watching of this KEY, Storage node knows whether a storage engine will be created to storage data locally;
Fault tolerance
- ETCD is a very central component during the process, as all coordination and scheduling information is done by it;
- Most Metadata is also stored in ETCD;
So if the ETCD is down, there will be a big impact on the whole system, then how to minimize the impact is very important:
- Firstly, if ETCD is down, In the extreme case, the data corruption in the ETCD won't be recovered. Therefore, the relevant node need to perform local backup operations after each Metadata change, and have the ability to restore the new data to new ETCD cluster;
- ETCD failures should not affect the availability of the entire system;
Negative Effect when ETCD is down:
- Affecting Metadata change, however this operation is low-frequency which is acceptable;
- If the Shard Leader node is corrupted at the same time, data written to this node will be temporarily re-written to other Shards, and the data in this node cannot be read temporarily;
- If the Shard Follower node is corrupted at the same time, which may affects the inconsistency of the replica data, but the data will be temporarily stored in the Leader node;