Replication
Overview
For the replication of distributed storage, consensus protocols such as Paxos, Raft, and ZAB are commonly used in the industry. More than half of these protocols will sacrifice certain performance to strictly ensure data consistency.
The scenario faced by LinDB is that the amount of writing is huge, and the requirements for data consistency are not high. It also allows short-term data inconsistency and eventually consistent. Therefore, LinDB adopts the strategy that when successfully written to the Leader the write operation is successful.
Written to Leader is successful has the following benefits:
- Improving write performance;
- Any machine can be deployed in the cluster, while Paxos, Raft, ZAB, etc. require at least 3 machines;
Written to Leader is successful, has the following problems:
- Data consistency problem: once the
Leaderis down, a newLeaderwill be elected, then the newLeadercopying new data may overwrite the data written by the oldLeader; - Data loss problem: once
Leaderis down, and the data block which was not copied toFolloweris also damaged at this time, this part of data will be lost;
In order to solve the above problems and try to ensure that data is not lost, LinDB adopts a multichannel replication scheme, as shown in the following figure:
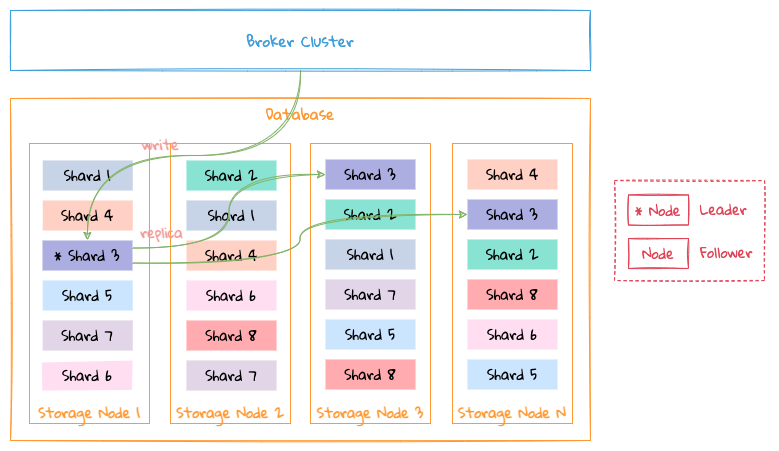
Take the data shard Shard 3 as an example:
- When
Node 1is aLeader,1-WALwrite channel is enabled,Node 1receives new data and writes it to the1-WALchannel, and replicating the data into1-WALchannel ofNode 2andNode 4; - When
Node 1is down andNode 2is elected as the newLeader, the2-WALwrite channel is enabled, andNode 2receives new data and replicating the data into2-WALchannel ofNode 4; - When
Node 1is up again,Node 1continue to copy the data into1-WALchannel that has not been copied toNode 2andNode 4to their corresponding1-WALchannels .Node 2will supplement the data in the2-WALchannel to the2-WALchannel ofNode 1;
That is, data in write channel flows from Leader . For example, the 1-WAL channel is always the Node 1 replication channel to Node 2 and Node 4, and the 2-WAL channel is always Node 2 replication channels to Node 1 and Node 4, 4-WAL channel is always Node 4 replication channel to Node 1 and Node 2, and so on,
TIP
Node 1 corresponds to the unique identifier 1 in the cluster, and so on for other nodes.
This way of replication solves the following problems:
- Avoid data inconsistency: only one node is responsible for the authority of the data for each channel, so there will be no conflict;
- Avoid data loss as much as possible: as long as the data which has not been copied in the old
Leaderis still persistent at disk, it will be copied to other replicas after it gets up again. If the data that has not been copied in the oldLeaderis lost, then which will be lost forever;
Preconditions for multichannel replication:
- Out of order is allowed: data written to multiple channels loses its order. Transactions are not required for Time series data scenarios faced by
LinDBso out of order is allowed.
TIP
Since a major feature of time series data is time correlation, LinDB also shards data by time according to this feature when storing data. Each time shard is a storage unit, so the actual replication channel is also stored with Units correspond one-to-one.
Local replication
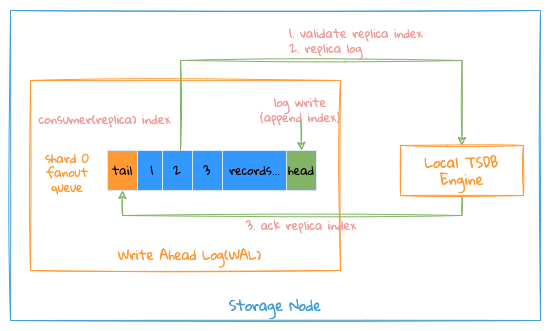
The entire Local Replication writing process is as follows:
- The system will start a writing goroutine for each
Shardreplication channel, this goroutine is responsible for all write operations on this channel, whatever it is aLeaderor aFollower; - First, data corresponding to
namespace/metric name/tags/fieldsinto the index file of the database will be written, and the correspondingmetric id/time series id/field idwill be generated, this operation is mainly about completing the conversion ofstring->int; Advantage of this conversion is that all data are stored in data types to reduce the overall storage size, because for each data point, metadata such asnamespace/metric name/tags/fieldsis occupied by such ascpu{host= 1.1.1.1} load=1 1514214168614, In fact, after converting toid, the storage will becpu => 1(metric id), host=1.1.1.1 => 1(time series id), load => 1(field id), simplified to1 1 1514214168614 =>1, please refer to index for the specific index structure; - If writing index operation fails, it is considered that the writing has failed, and the failure is composed of two cases`;
- Bad data writing format, such failures are directly marked as failures;
- Internal failure, the writing operations will be retried;
- When obtained
ID, data will be written into storage uint, this process is similar toLSM, which writes data into the memory database firstly, and directly write to the memory to achieve high throughput performance. After the size of memory data reaches the memory limit, theFlushoperation will be triggered. For details, please refer to Storage Format, Memory Database;
Here are two import replication Index for write operations:
Consume(Replica) Index: where the writing goroutine has been processed, each write operation will first verify whether theIndexis legal;Ack Index: which data in this channel has been successfully written and persisted to storage;
Here are a few things to note:
- The writing goroutine will consume the written data from the
WALchannel in order, so theReplica Indexis an ordered pointer, so it is easy to check with the persistedIndexto verify the data whether it has been written; - The
Flushgoroutine is used to synchronize theAck Indexto notify which data has been written successfully; - Since all write operations write into memory firstly, and then persist the data into corresponding file. If the system crashes during this process, as there is no
Ack Index, even if the data in the memory is lost, but when the goroutine starts again, it consumes the data in theWALchannel withAck Indexas the currentReplica Index. This consuming process achieved that data can be recovered after crashing;
Remote replication
Pick Node 1 as Leader in the above figure with 3 Replications replicating data from 1-WAL as an example:
Node 1 acts a Leader of the shard to accept written data from Broker, Node 2 and Node 4 are both Follower accepting the replication request of Node 1, meanwhile the 1-WAL channel is used as data write channel.
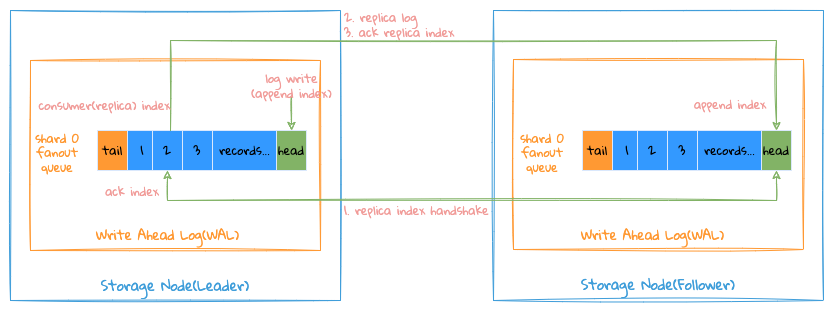
Index basic concept description:
Append Indexof each channel, indicating the writing position of the channel ;- Each channel retains each
Follower Consumer (Replica) IndexandAck Index, respectively indicating the position where eachFolloweris consumed (consumed but the request is still without successful consumption acknowledged) and position of successful consumption; Tail Indexof each channel: indicates the minimum value of allFollower Ack Index,WALbefore theIndexis deletable ;
The entire replication process is as follows:
Leaderwill start an independent goroutine for eachFollowerreplication, getFollower Consumer(Replica) IndexfromWALofLeaderthen send it toFollower;Followercompares theAppend IndexwithConsumer(Replica) Indexin localWAL;- On equal: return
Consumer IndextoLeaderasAck Index(normal case); - On not equal, return the
Append Indexin its own localWALtoLeader;
- On equal: return
- After
Leaderreceiving response, detect whether theAck IndexofFolloweris equal toConsumer(Replica) Index;- On equal: update the
Ack Indexof theFollower(normal case); - On not equal: here are some cases:
- On
Follower Ack Indexsmaller thanTail IndexofLeader WAL: this means thatFollowerlocalAppend Indexis too small whileLeaderhas no data at that position, thenFollowershould reset its ownAppend IndexasTail IndexofLeader; - On
Follower Ack Indexis greater than theAppend Indexof theLeader WAL: this means that theAppend Indexof theFolloweris too large, and theLeaderhas no data at this position, and theLeader WALneeds to be changed. Append Indexis raised toFollower Ack Index, andFollower Consumer(Replica) Indexis raised toFollower Ack Index`; - On
Followeris betweenTail IndexandAppend IndexofLeader WAL:Follower Consumer(Replica) Indexwill be reset toFollower Ack Index;
- On
- On equal: update the
The process of Leader and Follower to initialize the replication channel is similar to TCP three-way handshake.
Sequentiality
Generally speaking, multichannel replication does not guarantee the order of the overall data. In most cases, only one of the channels is used. It is necessary to ensure the order of replication of the channel. With sequentiality, it is easier to know which data has been copied. Which data has not been replicated.
To ensure the sequentiality of replication process, it is necessary to ensure the order of the following steps:
Leadersend replication requests in order;Followerprocesses replication request in order;Leaderresponses to replication request in order;
Since the entire writing and replication process is based on the GRPC Stream long connection and single-goroutine processing mechanism, the above conditions can basically be guaranteed.