集群协调
LinDB 中 Metadata 的协调变更操作由 3 种角色共同完成。
- Master:操作所有 Metadata 变更操作,并通过 ETCD 下发给集群里别的组件,Master 中 Broker 节点的选举出来;
- Broker:监听集群中所有状态;
- Storage:监听当前 Storage 所在的存储集群的状态;
整个集群的协调操作都是由 Master 来完成,那么为什么把这些重要的操作放在 Broker 上呢?
- Broker 其实是充当计算节点,包括读写操作。由于 Broker 需要知道下层所有 Storage 节点的状态信息,所以状态信息的协调任务被放在 Broker 中;
- Metadata 的变更不频繁,并且都是轻量操作;
- 需要多机房同一数据库的计算能力;
哪些信息需要处理?
- 数据库 DDL 操作;
- Storage 节点管理;
- 运行时参数调整;
- Storage/Broker 状态管理;
概述
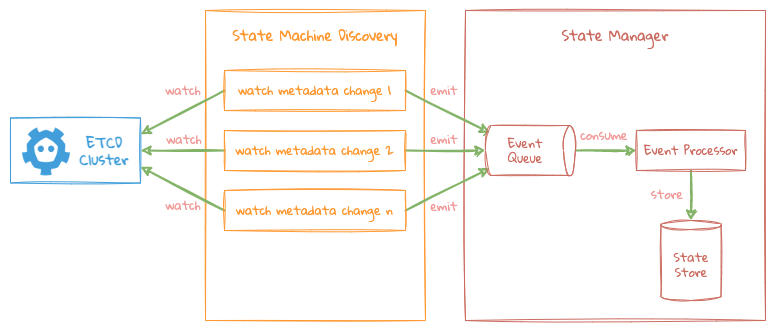
所有的调度操作都基于上图的基本框架逻辑处理,每种角色各自监听 ETCD 中所关心的数据变更操作。
- 每个角色针对自己所关心的 Metadata 启动一个异步线程进行监听对应 ETCD 中 Key 的变化,每个 Key 的变化都有一个独立的线程负责监听;
- 当所监听的 Key 发现变化之后,由监听线程把对应的事件提交给 State Manager 中的事件列队中,State Manager 会启一个全局线程统一来处理所有事件的变更逻辑,并把处理完的结果存储在 State Manager 的 State Store 中;
- 外部所有的状态信息的获取都直接查询 State Manager 的 State Store 中获取,无需再通过 ETCD ,以此来达到当 ETCD 出现问题时还可以通过 State Manager 内存中的数据进行工作;
Master
Master 负责主要的 Metadata 的变更,Master 通过抢占式从当前存活的 Broker 节点中选举出来,即每个 Broker 节点同时去注册 Master KEY ,谁先注册上成为 Master ;
同时每个 Broker 也会 Watch Master KEY,如果 Master KEY 上的信息丢失,重新进行选举,这样的好处是每个 Broker 都知道当前 Master 是哪个节点,可以转发一些请求到当前的 Master 节点上;
Master KEY: /{broker namespace}/master/node
选举成功的 KEY: /{broker namespace}/master/node/{broker node}
选举逻辑完成: /{broker namespace}/master/elected/{broker node}
Master 主要负责以下几种状态机:
- Storage Config State Machine;
- Database Config State Machine;
- Shard Assignment State Machine;
Storage config
Watch KEY: /{broker namespace}/storage/config
- 用户可以提交 Storage 集群配置信息给任意一台 Broker 节点,该 Broker 节点只是简单的把配置信息写到
/storage/config/{cluster name}下; - Master 根据配置信息为每个 Storage 集群建立一个 Storage Live Node State Machine 的 Watch 机制,以追溯每个 Storage 集群节点的存活情况;
- 每个 Storage Cluster 会 Watch Storage 节点的存活情况,并把该 Storage 整体的状态信息写到
/state/storage/cluster/{cluster name}下以供 Storage Cluster Status State Machine 使用;
每个 Storage Cluster 的 Watch 机制如下:
- 根据 Storage 集群的配置信息,与 Storage 集群的 ETCD 建立关系;
- Watch Storage 集群节点存活的 KEY:
/active/nodes(注意有别于与 Broker 的/active/nodes,这里对应的是 Storage 将要注册的信息); - 每个 Storage 节点启动的时候,需要注册节点信息到对应的 KEY 下:
/live/nodes/{storage node id};
Database config
Watch KEY: /{broker namespace}/database/config
- 用户可以提交数据库 DDL 到任意一台 Broker 节点,该 Broker 节点只作配置写入;
- Master 通过 Watch KEY 的变化,知道需要对哪个数据库进行分配操作,根据当前 Storage 集群的节点状态信息,生成 Shard Assignment ,并把 Shard Assignment 信息下发给对应的节点;
提示
Shard Assignment : 描述数据库每一分片 Shard 的详细信息:
Name: 数据库名
Option: 数据库存储引擎的配置信息
Shards: 各 Shard 的分配信息
每个 Shard 分配包括如下信息:
ShardID: 该 Shard 对应的 ID
Replicas: 该 Shard 下所有 Replicas 的信息,对应上面 Node ID 里面的信息
Shard assignment
Watch KEY: /{broker namespace}/database/assign
- Broker 通过 Watch 这个 KEY, 在数据分片数量变更时,根据目标 Storage 集群当前在线的节点情况,选举对应数据分成的 Leader 节点,并将选举结果信息下发至相应的节点;
Storage live node
Watch KEY: /{storage namespace}/live/nodes
通过监听对应 Storage 集群每个节点存活的情况,来控制该节点上的数据分片是否需要重新选举新的 Leader 节点,已经当前的副本的存活情况。
- 下线节点中有承担数据分片 Leader 的角色,则需要从当前存活的副本节点中选举对应的节点成为新的 Leader,如果当前没有存活的副本节点,则把该数据分片标识为下线状态;
- 下线节点只承担数据分片的副本角色,则从存活的副本列表中移除该节点;
- 上线节点,把该上节点添加到存活副本列表中,如果此时对应的数据分片为下线状态,选举该节点为 Leader,同时上线该数据分片;
Broker
Broker 主要负责以下几种状态机:
- Live Node State Machine;
- Database Config State Machine;
- Storage Status State Machine;
Live node
Watch KEY: /{broker namespace}/live/nodes
- Broker 启动的时候都会把自己的信息注册到 Watch KEY 下面,即
/live/nodes/{broker node}; - 通过 Watch KEY 的变化,每个 Broker 都知道当前 Broker 集群中存活的节点有哪些;
Database config
Watch KEY: /{broker namespace}/database/config
- 通过 Watch KEY 的变化,Broker 知道当前集群有哪些 Database 及其配置的配置信息;
Storage status
Watch KEY: /{broker namespace}/storage/state"
- Watch KEY 里面的信息由 Master 统一写入,Master 会 Watch 每个 Storage 集群各节点的存活情况,并把最终集群的信息写入到 Watch KEY 下面, 具体请看 Storage Live Node State Machine;
- 通过 Watch KEY 的变化,可以知道每个 Storage 集群整体状态信息;
- 处理查询请求时,通过该状态信息来请求对应 Storage 节点的数据;
- 处理写入请求时,通过该状态信息中获取目标数据分片的 Leader 节点,并建立对应的数据写入通道;
Storage
Storage 主要负责以下几种状态机:
- Live Node State Machine;
- Shard Assignment State Machine;
Live node
Watch KEY: /{storage namespace}/live/nodes
- Storage 启动的时候都会把自己的信息注册到 Watch KEY 下面,即
/live/nodes/{storage node}; - 通过 Watch KEY 的变化,每个 Storage 都知道当前 Storage 集群中存活的节点有哪些;
Shard assignment
Watch KEY: /{storage namespace}/database/assign
- 通过 Watch KEY 的变化, Storage 节点根据对应 Database 的 Shard 分配信息来确定是否需要在本地构建对应的数据存储引擎来存储数据;
容错
- 整个过程中 ETCD 成为了一个非常核心的组节,因为所有的协调及调度信息都是通过 ETCD 来完成。
- 大部分 Metadata 信息都存放在 ETCD 中;
因此如果 ETCD 出问题了对整个系统会产生很大的影响,那么怎么把影响做到最小是比较关键的:
- 首先 ETCD 挂了,极端情况 ETCD 中的数据损坏不能恢复了怎么办? 因此需要在每次 Metadata 变更之后相关节点都需要做好本地的备份操作,并有能力通过这些备份数据能还原到新的 ETCD 集群中;
- ETCD 出问题不应该影响整个系统的可用性,即不影响正常的读写操作;
限制:
- 影响 Metadata 的变更,但此操作本身为一个低频操作,是可被接受的;
- 如此时 Shard Leader 节点出现问题,写入该节点的数据,会临时写到别的 Shard 中,暂时不能读取该节点中的数据;
- 如此时 Shard Follower 节点出现问题,可能会影响副本数据不一致,但数据会暂存在 Leader 节点;