内存数据库
内存结构
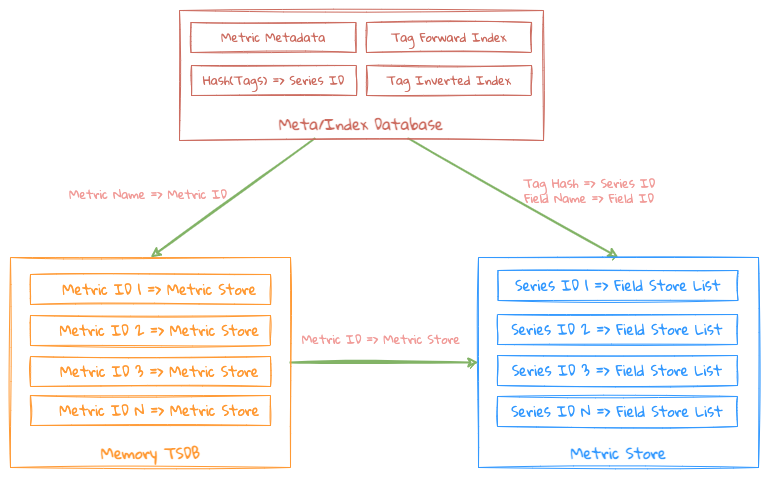
整个内存结构更像是一个内存时序存储,主要包括如下 2 大块组成:
- Metric Meta/Index: 主要存储了 Metric Metadata 和 Tags 的索引;
- Metric Metadata: 存储该 Metric 下面对应有哪些 Field 和哪些 Tag Keys,同时为每个 Tag Key 生成一个数据库级别的全局唯一的 ID,方便 Tag Index 在底层 KV Store 中的存储;
- Metric Index: 主要是为每个 Metric Tag Key 下面的 Tag Values 做一个倒排索引,Term 是对应的 Tag Value, Posting List 为该 Metric 下对应的 Series ID ;
- Hash(Tags) => Series ID: 通过 Tags Hash Code 计算相应的 Series ID 是否已经存在;
- Metric Store: 主要存储了 Metric 下面的数据,即该 Metric 下面的所有对应 Series 的每个 Field 的数据;
- Field List(Field Store): 根据不同的 Field Type 存储该 Field 的实际数据
整个内存结构中维护了上面 2 个数据结构的 2 个映射关系。
Series ID 的唯一性
部分设计考虑了 OpenTSDB String => Int 的思路,考虑到时序数据的特点,Metric Name + Tags 这部分占用存储大头的数据存储在 Meta/Index 中: Filtering/Grouping 等操作将基于这部分数据来进行,实际存储数据时只存储到 Series ID 。
Metric 下的每一条 Series 线的唯一性通过 tags 来确定:对于 tags(ip=1.1.1.1, host=test.vm, zone=nt),先根据 tagKey 作排序,得到 host=test.vm,ip=1.1.1.1,zone=nt 。如果原始存储 tags 文本到 Series ID 的映射关系,会浪费过多的存储空间。权衡效率后,LinDB 通过对 tags 计算 hash 来记录 Series,关于碰撞机率可参考生日碰撞
一般化的哈希碰撞机率公式如下:

通过以上公式,计算得 64 位 hash 在不同的 tags 组合数下的碰撞概率见下表。其中 d 为取值空间,n 为数据集规模。 在监控领域下,Metric 下 tags 的组合数极少能达到 1M 量级,即使在该量级碰撞机率也极低。
| Tags组合数量 | 至少有2条Series出现碰撞的机率 |
|---|---|
| 100K | 0.000000000271 |
| 1M | 0.0000000271 |
| 10M | 0.00000271 |
| 100M | 0.000271 |
| 1G | 0.0271 |
写
整个写入流程如下:
- 首先通过 Metric Name 查询是否存在对应的 Metric Meta;
- 存在: 使用 Metric Meta 中的数据,找到对应的 Field ID 和 Series ID,如果存在直接返回相应的 ID,如果没有对应的 Field ID 和 Series ID 的话先生成对应的 ID,同时往 Index 里面写入引索数据;
- 不存在: 这种情况为一个新的 Metric, 返回生成对应的 ID,同时往 Index 里面写入引索数据;
- Index 使用 Roaring Bitmap 为存储 Series ID Posting List;
- 拿到 Metric ID/Series ID 之后,就可以操作 Metric Store,找到对应的 Field Store 写入即可;
这里需要注意的地方有,如果直接使用 Map 来存储 Metric Store 里面的 Map 的话内存的开销还是比较大的,因为本身已经都转换成了 Int,所以这里可以使用 Roaring Bitmap + Array 的数据结构来构建一个 Map 结构,在 Roaring Bitmap 中存储所有 Keys 的值,Key 在 Roaring Bitmap 中的位置就是 Array 的 Index ,所以读取的效率也可以保证,同时可以与倒排索引里面 Roaring Bitmap 保持一致。
深入 Roaring Bitmap 之后发现 Roaring Bitmap 内部是以 High Container + Low Container 的方式存储的,所以 Roaring Bitmap + Array 也可以使用这个思想来对进一步优化 Map 结构,即使用 Roaring Bitmap + []Array 的结构, Key 的高位使用 Roaring Bitmap 的 High Container 来存储, Key 的低位用 Low Container 来存储, Key 的高位对应一个 Array ,整体就是一个 2 维数组。这样就可以通过 Key 的高位来进行并行查询操作。
Flush
系统会定期检测当前系统中每个 Memory TSDB 是否已经超过了内存大,如果满足下面条件中的任何一种,都需要把内存中的数据 Flush 到磁盘上:
- 单个 Memory TSDB 的内存占用超过指定大小;
- 该个 Memory TSDB 距离上次 Flush 时间超过了一定的大小;
- 该 LinDB 实例总内存占用超过一定大小之后,Flush 哪些占用内存比较大的 Memory TSDB,以防止该实例 OOM;
文件结构请看 Storage SSTable。