查询
概览
参与查询的角色如下:
- Broker : 接收用户的查询,根据查询语句生成相应的执行计划,并下发到相应的 Storage 节点,同时会聚合各 Storage 节点返回的结果,生成最终的结果;
- Storage : 执行数据的过滤, DownSampling 和最简单的原子计算(即有一定的算子下推的能力);
整个查询顺序如下,这里不分是在 Broker 还是 Storage 上执行,只看整个查询过程:
- Query Language Plan
- Filtering
- Scan Time Series
- Grouping if need
- DownSampling
- Aggregation
- Functions
- Expressions
由于 LinDB 是用 Golang 实现,因此可以通过 Goroutine 就能很好的支持一个异步操作及高并发,但系统还是采用了 Goroutine Pool 的概念来更好的管理及处理这些异步 Task 。
整个查询过程都是异步完成,以异步 Task 的方式工作,即 Task A 只做一件事情,Task A 的结果可能是 Task B 的 Input ,但是 Task B 不会等待 Task A 结果的到来,而是以 Event 的方式 Trigger Task B,最终完成一个查询 Pipeline 执行。
这里需要特别说明的是,系统不会开几个 Goroutine 来完成一个请求,而是在不同的 Goroutine Pool 中完成,所有的 Task 都是没有返回值的,以 Event Driver 的方式进行处理。
下面举一个例子来说明,例如 Scan Goroutine Pool 只做 Scan 的操作,而不是启了一个 Goroutine Scan 数据,等待下一个 Task 结果再返回给上层 Task 来做合并,这样整个处理过程中各 Goroutine 还是会有等待行为,而是直接把 Scan 的结果直接给下一个 Task ,数据合并有专门的 Task 来完成,这样的好处是 Scan Goroutine 完成一个 Scan 操作之后,又可以做下一个 Scan 操作,可以更充分的利用系统资源。
尽量通过 Streaming 的方式来完成整个查询过程,以减少没有必要的对象创建带来的 GC 压力,同时也会对一些可以复用并且高频的对象进行 Pool 化,以提升内存的使用率。
根据不同的查询条件,可以 Plan 出如下几大类型的执行计划:
- Simple Query : 简单的聚合查询;
- Complex Query : 带 Grouping 的查询;
- Cross IDC Query : 跨 IDC 之间的查询;
简单查询
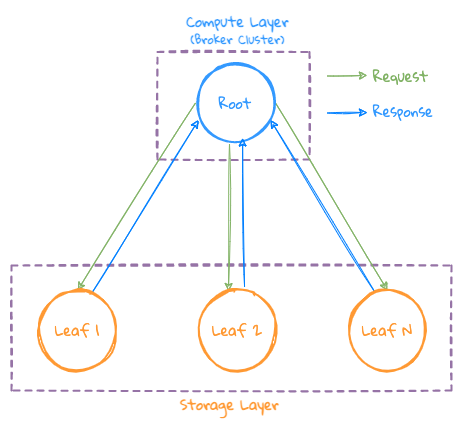
- 接收到用户请求的 Broker 节点作为 Root 节点,根据当前所需要查询的 Database 状态,执行 Plan 操作,并生成执行计划,并把查询请求发送给 Storage 集群相关的节点(Leaf 节点)执行;
- Leaf 节点根据查询条件执行 Filtering=>Scan=>Downsampling=>Aggreation 等操作;
- 由于没有 Grouping 操作,因此最终的结果可以直接返回给 Root 节点进行最终的聚合操作,并把最终结果返回给用户;
复杂查询
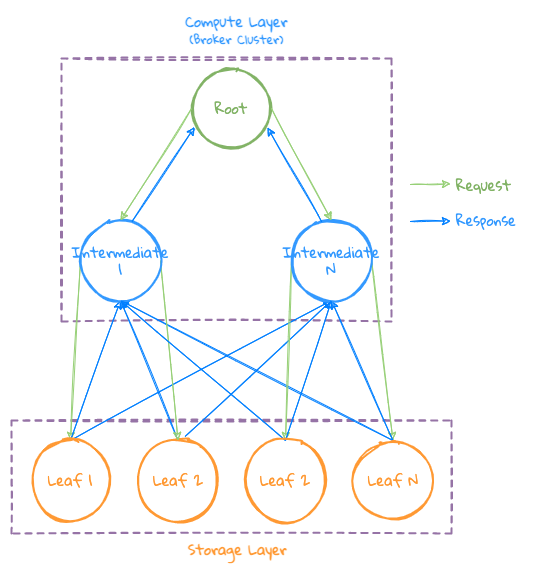
由于很多场景都需要通过 Grouping 来做更复杂的分析,有时还需要通过 Top N 求相应的数据,这时会返回大量的 Grouping 之后的数据,如果此时再把这些数据返回给一个计算节点的话,可能导致这个节点的内存成为瓶颈,为了解决这种场景带来的问题,引入了 Intermediate Broker 节点参与中间结果的计算,即:
- 多台计算节点协同参与部分 Grouping 的计算;
- 单机 Storage 节点向 Broker 节点发送数据时流式小批量发送,避免单节点 Storage 因查询数据过多而导致 GC 加剧甚至 OOM ;
整体处理过程如下:
- Root Broker 节点,根据集群计算并行度选择特定的 Intermediate Broker 来参与部分 Grouping 计算;
- Root 首先将请求下发给 Intermediate Broker ,再由 Intermediate Broker 下发任务给 Storage 节点,同时会带上所有 Intermediate Broker 信息,这样 Storage 节点就知道应该把结果数据回传给哪些节点;
- Storage 会按 Grouping 之后 Series 的 hash 值,把数据 Sharding 到指定的 Intermediate Broker 节点上,这样便能将相同的 Series 数据 Sharding 到同一台 Intermediate Broker 上进行 Aggregation 操作,以提高数据聚合的局部性,并保证数据的一致性;
- Intermediate Broker 收到数据后先进行数据的聚合,当查询信息中的所有 Storage 均已发送数据完毕后,说明完成了数据的聚合,然后开始进行表达式计算。表达式计算中可能包含局部排序,完成计算之后将结果发给 Root ;
- Root 进行最终的数据合并及排序操作,生成最终结果给用户;
跨机房查询
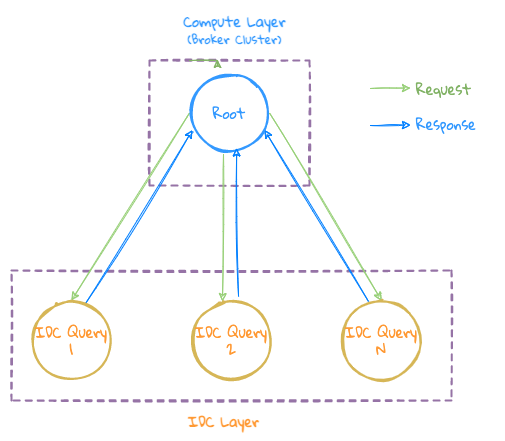
- LinDB 的跨 IDC 是做在 Query 层,因此可以把此类查询理解为把上面 2 种查询下发到各 IDC 之后的再在 Root 节点上做最终的聚合操作;
异常处理
- 查询超时或者异常导致部分节点没有把数据返回给上游节点,导致上游节点的 Task 一直是 Pending 状态,因此每个节点都会有一个 Task Manager 来管理每个请求处理的所有 Task 状态,来处理异常 Task
- 部分 Storage 节点有时由于没有对应的数据返回 Not Found ,需要处理这类异常;
- 正常异常处理;