

例排索引
主要作用是为方便对某个 Metric 下面 Tags 的 Filtering/Grouping 操作,同时也是为了提升整体的查询效率。
整个索引为一个倒排结构,类似 Lucene ,但是相比会更加简单,因为在时序这样的场景不需要做分词这样的操作。
结构
Metadata
主要存储 string->uint32 数据转换,类似经典的 OpenTSDB 设计思想。
Namespace
| Key | Value |
|---|---|
| Namespace(string value) | Namespace ID(uint32) |
Metric
| Key | Value |
|---|---|
| Namespace ID + Metric Name(string value) | Metric ID(uint32) |
Field
| Key | Value |
|---|---|
| Metric ID | Field List |
单个 Field 的结构如下:
Field ID: 在该 Metric 下是唯一的,存储数据的时候用该 ID
Field Name: 字段名
Field Type: 字段类型,如 Sum/Min/Max 等
Tag key
| Key | Value |
|---|---|
| Metric ID | Tag Key List |
单个 Tag Key 的结构如下:
Tag Key ID: 在该 Database 下是唯一的,存储 Index 的时候用该 ID
Tag Key : Tag Key(string value)
Tag value
| Key | Value |
|---|---|
| Tag Key ID | Tag Values Trie |
其中 Tag Value 以 Trie 结构存储该 Tag Key 下所有的 Tag Value 的值,同时通过 Trie 的结构为每个 Tag Value 生成一个该 Tag Key 下唯一的 Tag Value ID 。
Index
由于在 Metadata 中已经做了 string->uint32 的操作,因此在 Index 中其实都是按数字来存储,进一步减少存储空间。
Forward
| Key | Value |
|---|---|
| Series IDs(Roaring Bitmap) | Tag Value IDs(Array) |
TIP
Forward Index 和传统的索引有所不同,传统索引会把每一条写入的数据当成一个正向记录存储下来,对应时序里面就是一条条的 Time Series 对应的 Tags,而这些 Tags 经过 Metadata 里面的 string->uint32 转换之后,都变成了一串数据,所以可以把这些数据都压缩到一条 Forward Index 中。
Inverted
| Key | Value |
|---|---|
| Tag Value ID | Series IDs(Roaring Bitmap) |
查询
下面以一个例子的方式来说明 Filtering/Grouping 。
Filtering
如下表为一个 Metric(cpu) 下面 Tags 对应的正向数据,有 3 个 Tags 分别为 host/cpu/type
| Tags | Series ID |
|---|---|
| host=dev cpu=0 type=SCHED | 1 |
| host=dev cpu=1 type=SCHED | 2 |
| host=dev cpu=0 type=TIMER | 3 |
| host=dev cpu=1 type=TIMER | 4 |
| host=test cpu=0 type=SCHED | 5 |
| host=test cpu=1 type=SCHED | 6 |
| host=test cpu=2 type=SCHED | 7 |
| host=test cpu=3 type=SCHED | 8 |
| host=test cpu=0 type=TIMER | 9 |
| host=test cpu=1 type=TIMER | 10 |
| host=test cpu=2 type=TIMER | 11 |
| host=test cpu=3 type=TIMER | 12 |
如果把上表的数据,倒排一下,就形成了如下表的倒排结构,Posting List 直接用 Roaring Bitmap 来存储。
| Tag | Posting List |
|---|---|
| host=dev | 1, 2, 3, 4 |
| host=test | 5, 6, 7, 8, 9, 10, 11, 12 |
| cpu=0 | 1, 3, 5, 9 |
| cpu=1 | 2, 4, 6, 10 |
| cpu=2 | 7, 11 |
| cpu=3 | 8, 12 |
| type=SCHED | 1, 2, 5, 6, 7, 8 |
| type=TIMER | 3, 4, 9, 10, 11, 12 |
同时对 Tag 下面的 Tag Values 以前缀树的方式存储,以方便对 Tag Value 做过滤操作,如 host like dev* 这样的前缀过滤操作。加上上面的倒排结构之后,对于条件过滤操作就非常方便,如多个条件的操作只需要对多个 Posting List 做与/或操作即可,基本可以满足日常多个条件的 And/Or/Not 这样的过滤操作。
TIP
例如:
- Case 1: host = test or host = dev,就是 2 个 Posting list 的 ”与“ 操作
- Case 1: host != test,这种就是找到 host 下面所的 Series IDs 和 host = test 的 Series IDs,把这 2 个 Posting list 求一个 AntNot(Difference) 操作即可
同时基于这个倒排结构可能支持一些 Metadata 的查询,如想知道 host 这个 Tag 下面有哪些 Value 等。
Grouping
那么,如果不存储正向数据,怎么来解决按某个或者某几个 Tag Key 的 Group By 操作呢?如果我们像 Lucene 一样需要对 Tag Value 做分词的话,基本上是做不到通过反向来推导出正向的数据,但是在 TSDB 这样的场景里面,我们不需要对 Tag Value 做分词处理,所以还是可以通过反向的数据来反推出来正向的数据的。
如下图,已经把单条 Tag Key 的正向数据重新还原成 Tag Key/Value => Series IDs ,以方便理解。
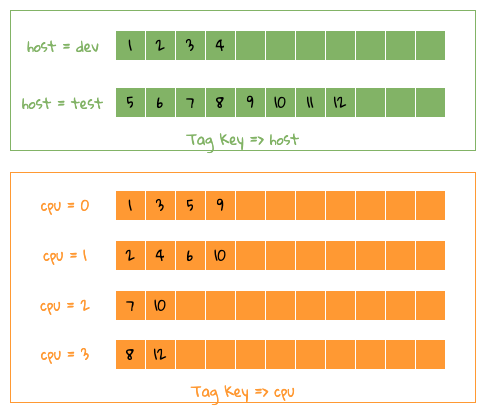 基于正向索引反推原始 Tag 组合
基于正向索引反推原始 Tag 组合
下面还是拿之前那个例子来说明,怎么来拿到 Group By host,cpu 这 2 个 Tag Key 的数据,如上图所示,其实从图中可以看到,整个操作就是一个归并操作,有 2 种做法。
- 因为每个数据都是排好序的,所以可以用 2 个堆来排序,即 host 和 cpu 分别放在一个堆里面,每次从每个堆里面取一个值,如果值相同,说明 2 者都满足,如 TSID = 0 对应的 host=dev,cpu=0 ,即可以找到相应的 Group By 数据,以此类推,遍历完 2 个堆里面的数据,就可以得到最终的结合,该方式会占用 CPU ,内存占用少;
- 使用类似 Counting Sort ,即预先分配好一个固定大小的数组,然后把 Series IDs 放在相应的数组下标里面,如下标为 1 中同时包括了 2 个 Tag Key 的数据,即是我们想要的,以此类推,可以拿到所有的数据, CPU 占用少,但是浪费内存;
再结合,Roaring Bitmap High/Low Container 的结构,一个 Container 里最多可以有 65536 个 uint16 值,所以内存的占用也可以得到控制,所以我们采用 Counting Sort 的方式来推导对应的正向数据,并且整体过程可以按一个个 Container 来并行处理。