复制
概述
对于分布式存储的复制,业界普遍采用的是基于 Paxos、Raft、ZAB 等一致性协议,这些协议的过半确认会牺牲一定性能来严格保证数据的一致性。
LinDB 面临的场景是写入量巨大,对数据一致性要求不是很高,也允许短暂的数据不一致,但最终一致,因此 LinDB 采用写入 Leader 成功即写入成功的策略。
写入 Leader 成功即成功有如下好处:
- 可以提高写入性能;
- 集群可部署任意台机,而 Paxos、Raft、ZAB 等则要求至少 3 台;
写入 Leader 成功即成功存在如下问题:
- 数据一致性的问题:一旦 Leader 挂了,选举出新的 Leader ,新 Leader 复制新的数据可能会覆盖老 Leader 已写入的数据;
- 数据的丢失问题:一旦 Leader 挂了,而此时正好未复制给 Follower 的数据块也损坏了,则这部分数据会被丢失;
为了解决上述问题,尽量保证数据不丢失, LinDB 采用多通道复制方案,如下图:
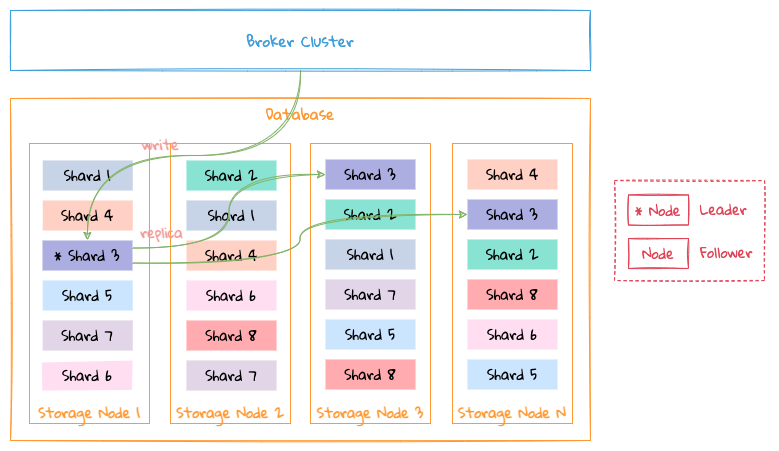
以数据分片 Shard 3 为例:
- 当 Node 1 作为 Leader 时,启用 1-WAL 写入通道, Node 1 接收新的数据写入到 1-WAL 通道中,并把 1-wal 通道中的数据复制到 Node 2 和 Node 4 的 1-WAL 通道中;
- 当 Node 1 挂了,选举出 Node 2 作为新的 Leader 时,启用 2-WAL 写入通道,Node 2 接收新的数据写入到 2-WAL 通道中,并把 2-WAL 通道中的数据复制到 Node 4 的 2-WAL 通道中;
- 当 Node 1 启动后,Node 1 会把 1-WAL 通道中还未复制给 Node 2 和 Node 4 的数据继续复制到它们对应的 1-WAL 通道中。 Node 2 会把 2-WAL 通道中数据补到 Node 1 的 2-WAL 通道中;
即以 Leader 为起点开启写入通道,如 1-WAL 通道永远是 Node 1 向 Node 2 和 Node 4 复制通道,2-WAL 通道永远是 Node 2 向 Node 1 和 Node 4 复制通道,4-WAL 通道永远是 Node 4 向 Node 1 和 Node 2 复制通道,以此类推,
提示
Node 1 对应在集群中唯一的标识为 1,其他节点以此类推。
这样的复制方式解决了如下问题:
- 避免了数据不一致的问题:每个通道的数据仅仅有一个节点负责数据的权威,所以不会有冲突问题;
- 尽量避免数据丢失问题:只要老 Leader 中还未复制的数据没有丢,再次起来后还是会复制到其他副本中。如果老 Leader 中还未复制的数据丢失了则这部分数据会被丢失;
可以采用多通道复制的前置条件:
- 允许数据乱序写入:数据写入了多通道后就失去了顺序性,LinDB 面临的时序数据场景并不需要保证事务所以是可以乱序写入的。
提示
由于时序数据一大特点是时间相关性,所以 LinDB 在存储数据的时候也根据这一特点按时间进行分片,每个时间分片为一个存储单元,因此实际的复制道通也跟存储单元一一对应。
本地复制
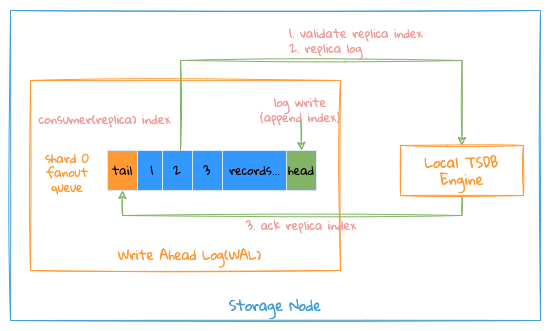
整个本地复制写入过程如下:
- 系统会为每一个 Shard 复制通道启一个写协程,该协程负责这个通道的所有写操作,包括作为 Leader 或者 Follower 时都有该协程来完成写操作;
- 首先把 namespace/metric name/tags/fields 对应的数据写入数据库的索引文件,并生成相应的 metric id/time series id/field id,主要完成 string->int 的转换;这样的好处是所有的数据存储都以数据类型来存储,以减少整体存储大小,因为对于每个数据点,namespace/metric name/tags/fields 这样元数据所占用,如 cpu{host=1.1.1.1} load=1 1514214168614, 其实转换成 id 之后,存储将由 cpu => 1(metric id), host=1.1.1.1 => 1(time series id), load => 1(field id),简化为 1 1 1514214168614=>1,具体的索引结构请查看索引;
- 如果写索引失败,认为本次写入失败,失败分为 2 种;
- 数据写入格式有问题,这类失败直接标示失败;
- 由于内部问题,这时写入失败需要重试;
- 通过索引得到 ID 后,再将数据写入到存储单元中,类似 LSM 先写内存数据库,直接写内存以达到高吞吐量的要求,内存数据到达内存限制之后,会触发 Flush 操作,具体请查看存储格式、内存数据库;
对于写操作,需要注意如下几个复制 Index:
- Consume(Replica) Index: 写协程已经处理到哪个位置,每写操作都会先验证该 Index 是否合法;
- Ack Index: 该通道中哪些数据已经写入成功并持久化到存储中;
这里需要注意如下几点:
- 写协程会按顺序从 WAL 通道中消费写入的数据,因此 Replica Index 是一个有序的指针,因此比较容易与已经持久化的 Index 作校验,以验证数据是否已经被写入;
- 由 Flush 协程来同步 Ack Index 通知哪些数据已经写入成功;
- 由于所有的写入操作先写内存,再由内存中的数据持久化到相应文件中,在这个过程中如果系统 Crash,由于没有 Ack Index,即使内存中数据丢失,但每次写协程启动的时候都以 Ack Index 为当前 Replica Index 来消费 WAL 通道中的数据,所以做到了在 Crash 之后也可以恢复丢失的数据;
远程复制
以上图 Node 1 为 Leader,3 个副本来复制 1-WAL 举例来说明:
当前 Node 1 为该数据分片 Shard 的 Leader 接受 Broker 的写入,Node 2 和 Node 4 都是 Follower 接受 Node 1 的复制请求,此时 1-WAL 通道作为当前的数据写入通道。
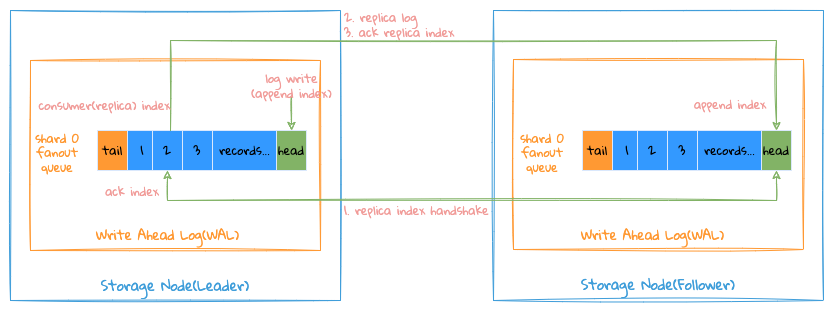
Index 基本概念说明:
- 每个通道的 Append Index,表示该通道写入数据的位置;
- 每个通道保留着每个 Follower Consumer(Replica) Index 和 Ack Index,分别表示每个 Follower 已消费的位置(已消费但是请求还在路上该位置还未确认消费成功)和消费已成功的位置;
- 每个通道的 Tail Index:表示所有 Follower Ack Index 的最小值,该 Index 之前的 WAL 可以被删除了;
整个复制流程如下所示:
- Leader 会为每个 Follower 的复制启动一个独立的协程进行处理,从 Leader 的 WAL 中获取该 Follower Consumer(Replica) Index 的数据发给 Follower ;
- Follower 接收到数据后对比本地 WAL 的 Append Index 是否等于 Consumer(Replica) Index;
- 如果等于则写入并将 Consumer Index 作为 Ack Index 返回给 Leader(正常情况下);
- 如果不等于,则将自己本地 WAL 的 Append Index 返回给 Leader;
- Leader 接收到响应之后,判断 Follower 返回的 Ack Index 是否等于 Consumer(Replica) Index;
- 如果等于则更新该 Follower 的 Ack Index(正常情况下);
- 如果不等于,则分如下几种情况:
- 当 Follower Ack Index 小于 Leader WAL 的 Tail Index ,说明 Follower 本地的 Append Index 过小,Leader 已无该位置的数据了,所以需要 Follower 重置下自己的 Append Index 为 Leader 的 Tail Index ;
- 当 Follower Ack Index 大于 Leader WAL 的 Append Index ,说明 Follower 本地的 Append Index 过大,Leader 已无该位置的数据了,需要将 Leader WAL 的 Append Index 提高到 Follower Ack Index ,同时将 Follower Consumer(Replica) Index 提高到 Follower Ack Index;
- 当 Follower 在 Leader WAL 的 Tail Index 和 Append Index 之间,则需要将 Follower Consumer(Replica) Index 重置为 Follower Ack Index 即可;
Leader 与 Follower 初始化复制通道的过程类似 TCP 三次握手。
顺序性
多通道复制总体来说是不保证整体数据的顺序性,绝大多情况下只使用其中的某一个通道,需保证该通道的复制的顺序性,有了顺序性更容易知道哪些数据已经被复制了哪些数据还未被复制。
要想保证复制过程的顺序性,需要保证以下几个环节的顺序性:
- Leader 复制请求的顺序性发送;
- Follower 端对复制请求的处理是顺序性;
- Leader 端对复制请求的响应需要保证是顺序性;
由于整个写入与复制过程都是基于 GRPC Stream 长连接加单协程处理机制,因此基本可以保证上述几个条件。