Storage
All data of LinDB will be stored on the local disk, and there are different storage structures according to different data types:
Metirc Metadata: storeMetric Nameand its underlyingFields/Tag Keys;Tags(Series) Index: store allTagsunder aMetric, this part is divided into2data types;- Forward:
Tagscorresponding toSeries ID; - Inverted: The inverted index of
Tag Key/Value, whereSeries IDare binding toTag Value.Series IDset is compressed stored by RoaringBitMap ;
- Forward:
Data: Storage ofData Pointunder allTime Series;
All the above data types are stored in a common underlying KV Store.
Time series characteristics
Before talking about storage, let's talk about the characteristics of time-series, as shown in the figure:

Time series data characteristics (according to its time characteristics, it can be divided into time-invariant and time-variant data)
Time Series=>Metric + Tags: This part of the data is basically a string, and this data occupies the bulk of the data packet, but it will not vary with time flows. Converting these strings into numerical values for storage to reduce storage costs;Fields: This part of the data is basically numeric and changes with time, but the numeric type is easy to compress;
Storage structure
Database
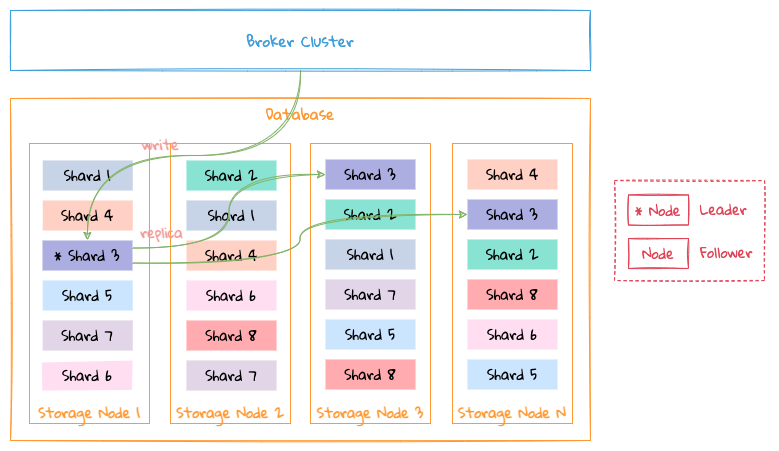
- The data of a database are distributed on different nodes of the
Storagecluster according toShard; - A
Shardcan have multiple replicas, please see Replication for details;
Shard
├─ db_test_1
| ├─ meta
| | ├─ namespace
| | ├─ metric
| | ├─ field
| | ├─ tagkey
| | └─ tagvalue
| └─ shard
| ├─ 1
| | ├─ inverted
| | ├─ forward
| | └─ segment
| | ├─ day
| | | ├─ 20190101
| | | | ├─ 01
| | | | ├─ 02
| | | | └─ 23
| | | └─ 20190102
| | ├─ month
| | | ├─ 201901
| | | | ├─ 01
| | | | ├─ 02
| | | | └─ 31
| | | └─ 201902
| | └─ year
| | ├─ 2019
| | | ├─ 01
| | | ├─ 02
| | | └─ 12
| | └─ 2020
| └─ 2
└─ db_test_2
The storage directory above describes how data are stored on a Storage node.
Taking the data structure of a single database on a single node as an example:
meta: store allmetadata, at database level:namespacemetricfieldtag keytag value
shard: A database will have multipleshards on a single node, and eachshardhas the following data:index: store forward and reverse indexes;segment: store the data of each time slice;
See Index for the structure of meta and index.
All data are divided into different parts by the Interval of the database to store specific data in time slices:
- The time series has strong time correlation, which makes it easier for querying;
- Convenient for handling
TTL. If the data expires, just delete the corresponding directory directly; - There are multiple
segmentsunder eachshard, and eachsegmentstores the data of the corresponding time slice according to the correspondinginterval; - Why are there many
data familiesstored according tointervalunder eachsegment? This is mainly because the main problem solved byLinDBis to store a large amount of monitoring data. The general monitoring data is basically written at the latest time, and basically no historical data will be written. The data storage of the entireLinDBis similar to theLSMmethod, in order to reduce the merge operation between data files which leads to write amplification. then the re-sharding policy ofsegmenttime slice is adopted.
The following is an example of interval being 10s:
segmentis stored by day;- Each
segmentis divided intodata familyby hour, onefamilyper hour, and the files in eachfamilystore specific data in columns;
KV store
└─ kv_store_1
├─ CURRENT
├─ LOCK
├─ MANIFEST-000010
├─ OPTIONS
├─ family_1
| ├─ 000001.sst
| ├─ 000002.sst
| ├─ 000004.sst
| └─ 000008.sst
├─ family_2
| ├─ 000011.sst
| ├─ 000012.sst
| ├─ 000014.sst
| └─ 000018.sst
└─ family_3
The whole KV Store is similar to LSM, but it is different from LSM. The main differences are as follows:
- There is no
Memory Table, because the whole system has aMemory Databaseto store all recently data, and these data will be directly written to theKV Storelater; Key's type isuint32, because allstringwill be converted touint32according to the timing characteristics, so the underlyingKV Storeis directly designed as anuint32 => binarystructure;
The directory structure is very similar to rocksdb and supports column family.
CURRENT: record the currently validMANIFESTfile;LOCK: file lock to prevent multiple processes from opening the sameKV Store;MANIFEST:change logof allsstablechanges, including somechange logofsequence, etc.;OPTIONS:KV Storeconfiguration information, including configuration information at eachcolumn familylevel;KV Storecan store multiplecolumn families, and eachfamilystores multiplesstablefiles;
Compaction
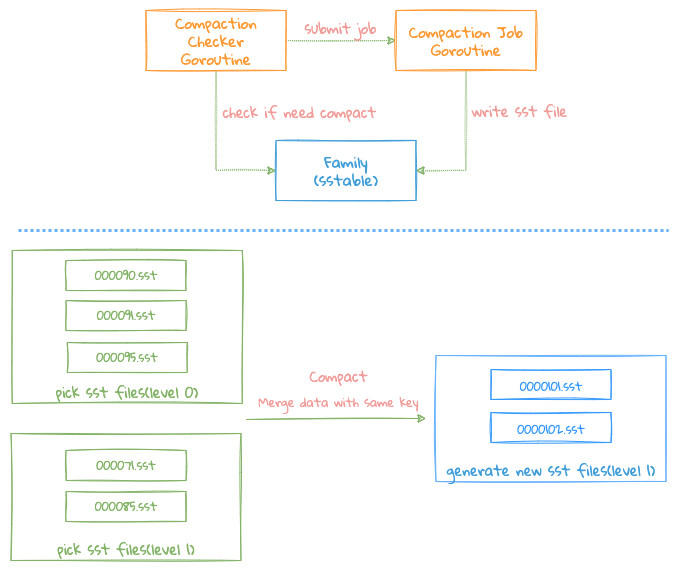
- Each
KV Storewill start aGoroutineperiodically toCheckwhether there are too many files in eachFamily Level 0and meet the conditions ofCompaction; - When the conditions are met, the corresponding
Familywill be notified to executeCompaction Job, if anotherCompactionjob is being executed, this operation will be ignored, all operations will only be done in oneGoroutine,of which the benefit is lock-free , becauseCompaction Jobis a very heavy operation, and if locking is required, it may affect the writing of new files
Compaction mainly merges the files in Level 0 into Level 1. Currently, LinDB has only 2 Level, which is different from LevelDB.
Compaction condition: any one of the following conditions will trigger the Compact task:
- the number of files in
Level 0exceeds the number of files configured;
There are 2 merge process:
- Directly moving the files of
Level 0toLevel 1, but the conditions ofcompactshould be met: the number of files ofpick files from level 0is1, the number of files ofpick fiels from level 1is1The number of files is0, that is, only one file needs to be merged, just modifyMetadata; - Need to combine multiple files into one large file;
The Compact process is as follows:
- Select the file that needs
Compact, firstly select the currentlevel 0file, then traverse eachlevel 0file, presskey rangeto get the overlapping file fromlevel 1, why is here? Fetchlevel 1files by eachlevel 0file, not by the finalkey rangeinlevel 0. Because thekeysof the entirelevel 0file may be relatively hashed, so if we take the finalrange, we may get a large range. E.g:
for example:
Level 0:
file 1: 1~10
file 2: 1000~1001
Level 1:
file 3: 1~5
file 4: 100~200
file 5: 400~500
- If we press the final range of level 0, 1~1001, this will take out all the files of level 1
- If we take it according to the range of each level 0, we only need to take the file 3 (1~5) in the end.
- The entire
compactprocess is actually a multi-way merge process. Since thekeyis sorted whenflushwrites files,compactonly needs to read each file in order, and pressThe order of keycan traverse the data from these files;
- During the process, the data with the same
keyneeds to be merged. The merging process needs to be merged according to different data types, and theMerger Interfaceneeds to be implemented; - If
keydoes not need the merge operation, write the corresponding data directly to the file, which can reduce unnecessary serialization operations;
- Once
compactmerging and writing files is successfully completed, submittingVersion EdittoVersion Setwill be taken. At this time,Version Editincludes newly written files and old files that need to be deleted. This process requires locks; - Delete those useless files: such as files that have been merged, or some intermediate result files after failure. It should be noted here that the cleanup operation must be done after the
Version Editis successfully submitted to theVersion Set, otherwise which may leads to data file confusion;
TIP
- Version Edit: Similar to LevelDB, a Version Edit will be recorded for each file write operation, and Version Edit will record new files/deleted files, so that when the system restarts or crashes, just reload the Version Edit Log again. There are those that mention the whole useful document;
- Version Set: record which files are currently stored and available;
Rollup
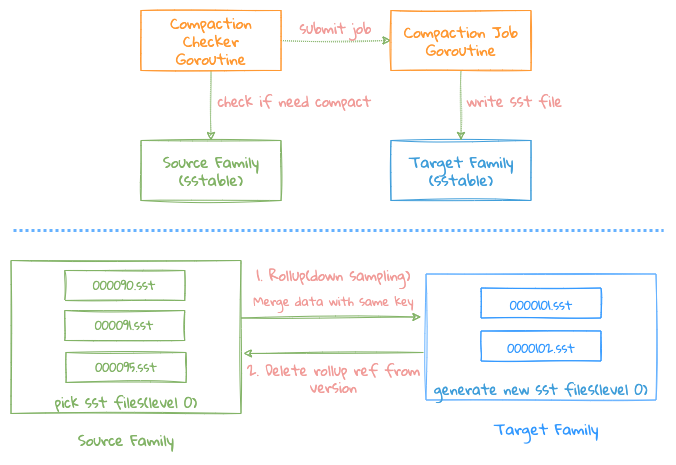
Rollup Job is a special Compact Job, which mainly deals with data reduction (DownSampling), namely 10s->5m->1h, its core logic is same as Compaction Job, the main differences are as follows :
Source Familymerges data intoTarget Familyto operate2Family;- After the merging is completed, delete the files that need
RollupinSource Family Version, and record the files that have beenRollupinTarget Family Versionto prevent duplicate data merging;
SSTable layout
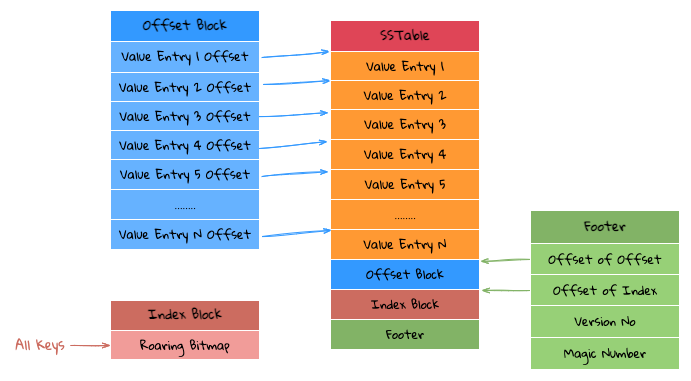
The structure of each SSTable is shown in the figure above, and it mainly has the following components:
Footer Block: StoringMagic Number(8 Bytes) + Version(1 byte) + Index Block Offset(4 bytes) + Offset Block Offset(4 bytes), which can be accessed through bothIndex Block OffsetandOffset Blockto read contents ofIndex BlockandOffset Block;Index Block: UsingRoaring Bitmapto store all theKeysin the currentSSTablefile, as allKeyareuint32, so we can directly useRoaring Bitmapto store, such benefits is that we can useRoaring Bitmapto determine whether aKeyexists, and at the same time we can also know the position of thisKeyin thisRoaring Bitmap;Offset Block: store all theOffsetofValue Entry, and eachOffsetis stored with a fixed length, so if it is found in theNthposition in theIndex Block, TheOffsetof thatValue Entryis the data pointed to byN * Offset Length;Value Entry: store theValuecorresponding to eachKey/Value, because theKeyis already stored in theIndex Block, so theValue Entryonly needs to store theValuein theKey/Value;
The advantage of this is that the compression of Key can be done well, and Roaring Bitmap has done a lot of optimization on Bitmap, Get data through Key is very efficient, because it is not like LevelDB, binary searching Key in the middle process are not required, and the Bitmap can be resident in memory.
Based on the above storage structure, the entire query logic is as follows:
- Through
Index Block, we can directly know whether the queriedKeyexists. If it does not exist, return it directly. If it exists, get the first position (Index) in theBitmap; - First jump: According to the
Indexobtained above, inOffset Block, after skippingIndex * Offset Length, we can getValue Entry Offset(Position); - The second jump: According to the
Positionobtained above, skip thePositionat the beginning of the file and then the desiredValuecan be read directly;
If we want to do the Scan operation, just directly read the sequence based on the Index Block and Offset Blcok.