

Memory database
Memory structure
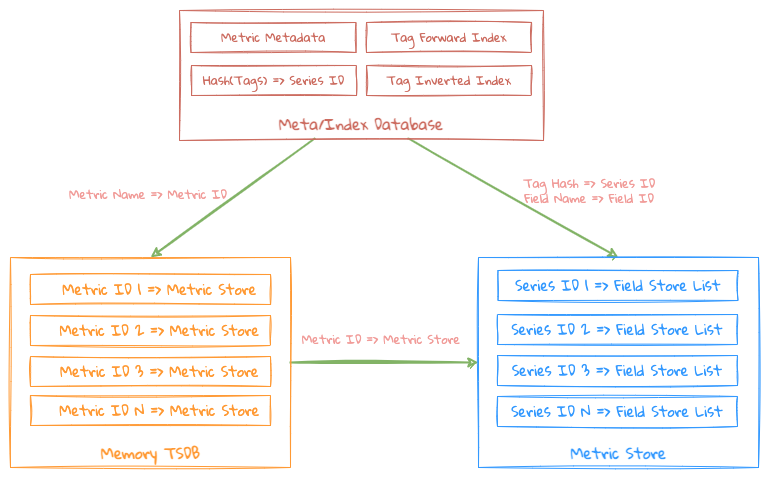 Memory database
Memory database
The entire memory structure is more like a memory sequential storage, which mainly consists of the following 2 blocks:
- Metric Meta/Index: It mainly stores the indexes of Metric Metadata and Tags;
- Metric Metadata: Store which Field and which Tag Keys correspond to the Metric, and generate a database-level globally unique ID for each Tag Key, which is convenient for Tag Index Storage in the underlying KV Store;
- Metric Index: Mainly to make an inverted index for the Tag Values under each Metric Tag Key, Term is the corresponding Tag Value, Posting List is the corresponding Metric Series ID;
- Hash(Tags) => Series ID: Calculate whether the corresponding Series ID already exists through Tags Hash Code;
- Metric Store: It mainly stores the data under the Metric, that is, the data of each Field corresponding to the Series under the Metric;
- Field List(Field Store): Store the actual data of the Field according to different Field Type
The 2 mapping relationships of the 2 data structures above are maintained in the entire memory structure.
Uniqueness of series ID
Part of the design considers the idea of OpenTSDB String => Int, and considering the characteristics of time series data, the Metric Name + Tags part of the data that occupies the bulk of the storage is stored in Meta/Index: Filtering/Grouping and other operations It will be based on this part of the data, and only store the Series ID when actually storing the data.
The uniqueness of each Series line under Metric is determined by tags: for tags(ip=1.1.1.1, host=test.vm, zone=nt), first sort according to tagKey , get host=test.vm,ip=1.1.1.1,zone=nt. If the mapping relationship between tags text and Series ID is stored originally, it will waste too much storage space. After weighing the efficiency, LinDB records the Series by calculating the hash of the tags. For the collision probability, please refer to Birthday Collision
The generalized hash collision probability formula is as follows:
 hash formula
hash formula
Through the above formula, the calculated collision probability of 64-bit hash under different combinations of tags is shown in the following table. where d is the value space and n is the size of the dataset. In the monitoring field, the number of combinations of tags under Metric can rarely reach the level of 1M, and even at this level, the collision probability is extremely low.
| Number of Tag combinations | Chance of collision with at least 2 Series |
|---|---|
| 100K | 0.000000000271 |
| 1M | 0.0000000271 |
| 10M | 0.00000271 |
| 100M | 0.000271 |
| 1G | 0.0271 |
Write
The entire writing process is as follows:
- First query whether there is a corresponding Metric Meta through Metric Name;
- Exist: Use the data in Metric Meta to find the corresponding Field ID and Series ID, if it exists, return the corresponding ID directly, if there is no corresponding Field ID and Series ID, Mr. into the corresponding ID, and at the same time write the index data into the Index;
- Does not exist: In this case, it is a new Metric, return the corresponding ID, and write the index data into Index at the same time;
- Index uses Roaring Bitmap to store Series ID Posting List;
- After getting the Metric ID/Series ID, you can operate the Metric Store and find the corresponding Field Store to write;
The points to note here are that if you directly use Map to store Map in Metric Store, the memory overhead is still relatively large, because it has been converted into Int, so Roaring can be used here. Bitmap + Array** data structure to build a Map structure, store all Keys values in Roaring Bitmap, the position of Key in Roaring Bitmap is Index of Array, so The efficiency of reading can also be guaranteed, and it can be consistent with the Roaring Bitmap in the inverted index.
After delving into Roaring Bitmap, it is found that Roaring Bitmap is stored in the form of High Container + Low Container, so Roaring Bitmap + Array can also use this idea to further optimize the Map structure, that is, use ** The structure of Roaring Bitmap + []Array**, the high bit of Key is stored in High Container of Roaring Bitmap, the low bit of Key is stored in Low Container, the high bit of Key corresponds to an Array **, the whole is a 2-dimensional array. In this way, parallel query operations can be performed through the high bits of Key.
Flush
The system will periodically check whether each Memory TSDB in the current system has exceeded the memory size. If any of the following conditions are met, the data in the memory needs to be Flush to the disk:
- The memory usage of a single Memory TSDB exceeds the specified size;
- The Memory TSDB has exceeded a certain size since the last Flush;
- After the total memory usage of the LinDB instance exceeds a certain size, Flush which occupies a large amount of memory Memory TSDB to prevent the instance OOM;
See Storage SSTable for the file structure.