

Query
Overview
The roles involved in the query are as follows:
- Broker: Receive user query request, generate the corresponding execution plan according to the query statement, then deliver it to the corresponding Storage node, and aggregate the results returned by each Storage node to build the final result;
- Storage: perform data filtering, DownSampling and the simplest atomic calculation (that is, there is a certain ability to push down operators);
The entire query sequence is as follows, here it does not matter whether it is executed on Broker or Storage, just an entire query process:
- Query Language Plan
- Filtering
- Scan Time Series
- Grouping if need
- DownSampling
- Aggregation
- Functions
- Expressions
Since LinDB is implemented in Golang, an asynchronous operation and high concurrency can be well-supported through Goroutine, but the system still uses the concept of Goroutine Pool to better manage and handle these asynchronous operations Task.
The entire query process is completed asynchronously and works in an asynchronous Task way, that is, Task A only does one thing, the result of Task A may be the Input of Task B, but Task B It will not wait for the arrival of the result of Task A, but Trigger Task B in the way of Event, and finally complete the execution of a query Pipeline.
It should be noted here that the system will not open several Goroutine to complete a request, but complete it in different Goroutine Pool, all Task have no return value, and Event Driver way of processing.
Let's take an example to illustrate. For example, Scan Goroutine Pool only performs Scan operation, instead of starting a Goroutine Scan data, waiting for the next Task result and returning it to the upper Task for merging, In this way, each Goroutine will still have waiting behavior during the whole processing process, but the result of Scan is directly sent to the next Task, and the data is merged with a special Task to complete, the advantage of this is the Scan Goroutine **After completing a Scan operation, you can do the next Scan operation, which can make full use of system resources.
Try to use Streaming to complete the entire query process to reduce the GC pressure caused by unnecessary object creation, and also Pool some reusable and high-frequency objects to improve memory. usage rate.
According to different query conditions, you can Plan the following types of execution plans:
- Simple Query: simple aggregation query;
- Complex Query: query with Grouping;
- Cross IDC Query: query across IDC;
Simple query
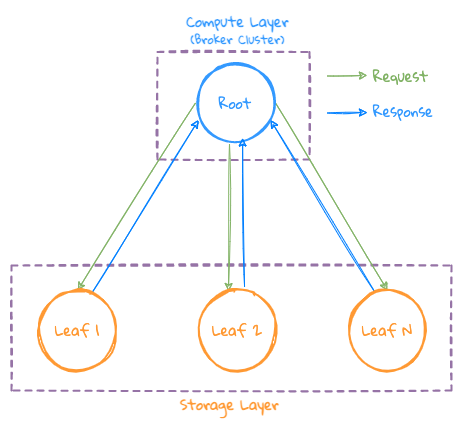 Simple query
Simple query
- The Broker node that receives the user request is used as the Root node, executes the Plan operation according to the current Database status to be queried, generates an execution plan, and sends the query request to the Storage cluster related The node (Leaf node) executes;
- The Leaf node performs operations such as Filtering=>Scan=>Downsampling=>Aggregation according to the query conditions;
- Since there is no Grouping operation, the final result can be directly returned to the Root node for the final aggregation operation, and the final result is returned to the user;
Complex query
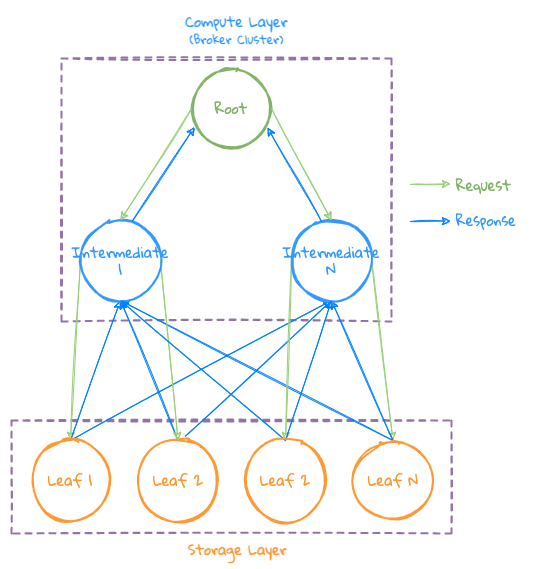 Complex query
Complex query
- In some scenarios, when Grouping is performed and then Top N is obtained, a large amount of data after grouping will be returned. If these data are returned to a computing node at this time, the memory of this node may become a bottleneck. Therefore, Introduced Intermediate Broker nodes to participate in the calculation of intermediate results
- The execution plan will select a specific Intermediate Broker to participate in the calculation according to the number of clusters in the currently available Broker nodes.
- The Root first sends the request to the Intermediate Broker, and after the Intermediate Broker completes the query task, the Root sends the task to the Storage node
- Storage will shard the data to the specified Intermediate Broker node according to the hash value of the Series after grouping, so that the same Series data can be sharded to the same Intermediate Broker for Aggregation operation to improve the locality of data aggregation
- Finally, each Intermediate Broker node returns its own calculation result to the Root node, and the Root merges to generate the final result
Cross-IDC Query
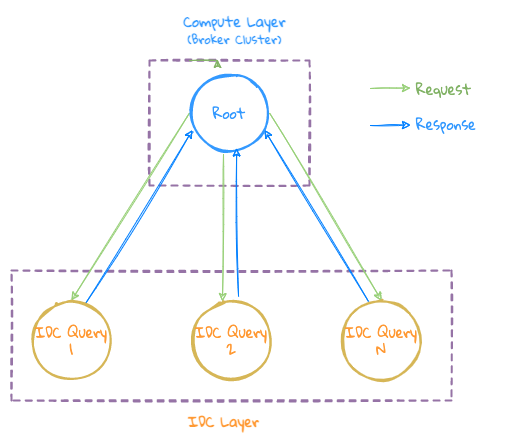 Cross idc query
Cross idc query
- LinDB's cross-IDC is done at the Query layer, so this kind of query can be understood as a re-aggregation operation after the above two queries are sent to each IDC
Error handle
- Query timeout or exception causes some nodes not returning data to the upstream node, so the task of the upstream node will at Pending state all the time. Therefore, each node will have a Task Manager to manage all the task states processed by each request to handle abnormal tasks.
- Partial Storage nodes sometimes return Not Found because there is no corresponding data, and need to handle such exceptions;
- normal exception handling;